本文将介绍本人所负责的问题一部分, 即对十年的引航中断数据进行分析, 并且得出相应的结论.
问题分析
- 项目提供的数据集给出了 2011-2020 共 10 年发生引航中断的情况统计, 其中导致引航中断的原因包括大风管制和能见度不良两类, 本题中暂不考虑能见度不良情况的分析, 只关注大风管制的分析. 请筛选出大风管制的情况统计, 统计大风管制日的风向、风级情况
注意: 风向和风级情况每日可能不是稳定的, 请设计数据处理规则, 能够有效地代表当日的风向、风级情况.
要求运用数据可视化的方法展示统计结果, 并文字说明风向和风级的数据处理规则, 附 XLSX 文件, 包括全部大风管制日的风向和风级. (15 分)
- 根据上一问中的分析, 建模分析不同风向和风级对触发引航中断的影响, 要求展现出 10 年间的影响情况, 并给出触发引航中断的风向和风级规律(可以是各因素的独立阈值, 也可以是双因素耦合的阈值). (15 分)
- 数据样例介绍:
- Sheet 1:2020年通航管制情况统计表——2020年引航中断时间的汇总, 其中本题只考虑大风管制的情况, 分别包括引航暂停的日期、暂停起止时间和暂停时长.
- Sheet 2:2020年1月8日洋山港海事局工作报告——使用其中的舟山附近沿海当日气象简报.
- Sheet 3:观测线6警戒区——经过观测线的船舶信息记录, 使用其中的船名、船舶种类、船舶长度、报告线名称、船舶航向、船舶航速、穿越时间、经度和纬度等信息.
观察发现所给的数据表格格式不一, 为了能够使用统一方式对数据进行挖掘处理, 需要将所有文件整合为 XLSX 格式.
按年顺序读取源表格文件后, 读取首页的 sheet 并且读取对应的日期. 在这个过程中, 还涉及了对于 sheet 格式上的剪裁处理和对字符串的重整化.
由任务要求可知, 需要整理大风管制引起的引航中断, 因此可以提取大风管制对应的日期并查询当天海面的天气情况.
而在该任务提供的数据文件中, 天气信息都是纯粹文本, 我们需要对其中的有效信息进行提取. 所以在这里我们选择了使用正则表达式进行筛选.
读取到各年大风管制日期下的风向风级后, 就可以使用 OriginPro 软件提供的绘图功能对(风向, 风级)信息进行统计并且总结规律.
任务一所涉及的代码根据需求被分为两个部分:classifier.py, calcute.py. 前者进行数据的读取, 后者进行数据的整理.
读取数据
#classifier.py
#! -*- coding=utf-8 -*-
from numpy import NaN
import pandas as pd
import re
import openpyxl
import pyexcel as p
import xlwings as xw
import shutil
years=[str(x) for x in range(2011,2020+1)]
for year in years:
#按年读取表格文件###############################################
parentpath=r"./Project02-Data-31/任务一-引航中断-气象统计数据"
path=parentpath+r'/'+year+r"年气象统计.xlsx"
#将新的mainsheet写入原来的表格而不删除其余的sheet
if int(year)>=2019:
#2019年和2020年文件为.xls格式, 转为.xlsx格式
p.save_book_as(file_name=path[:-1],dest_file_name=path)
f=pd.ExcelFile(path)
wb=xw.Book(path)
SheetNames=f.sheet_names
mainsheet=pd.read_excel(path,sheet_name=SheetNames[0])
#将sheet整理为和2019年以前相同的格式(即删除表头并日期列调整至第一列)
mainsheet=mainsheet.iloc[1:,1:]
orisht=wb.sheets(SheetNames[0])
orisht.delete()
sht=wb.sheets.add(name=year+'年影响通航',before=SheetNames[1])
sht.range('A1').value=mainsheet.values
wb.save(year+r"年气象统计.xlsx")
wb.close()
file=year+r"年气象统计.xlsx"
shutil.copy(file,parentpath)#将生成的文件覆盖在源文件上
#########################################################
f=pd.ExcelFile(path)
#获取工作表名称
SheetNames=f.sheet_names
#检查是否读取成功
print(SheetNames)
#读取第一张sheet
mainsheet=pd.read_excel(path,sheet_name=year+'年影响通航')
#读取第一页的文件并获得一些基本数据
rowNum=mainsheet.shape[0]
#读取第一页sheet的第一二列的有效数据
datePlus=mainsheet.iloc[2:rowNum-3,[0,1]]
datePlus=datePlus.dropna(axis=0,how='any')
#获取当年大风管制日期
date=datePlus.iloc[:,0]
#检查读取的大风管制时间段
print(date)
#将时间段拆分为单天
Date=[]
for i in range(date.shape[0]):
date.iloc[i]=date.iloc[i][5:]
series=[]
if '-' in date.iloc[i]:
###########对.和-进行定位###############
loc1=date.iloc[i].index('.')
loc2=date.iloc[i].index('-')
######注意去除日期单元格中偶尔出现的中文##
begin=int(re.sub('[\u4e00-\u9fa5]', '',date.iloc[i][loc1+1:loc2]))
end=int(re.sub('[\u4e00-\u9fa5]', '',date.iloc[i][loc2+1:]))
month=str(re.sub('[\u4e00-\u9fa5]', '',date.iloc[i][:loc1+1]))
for j in range(begin,end+1):
if month+str(j) not in Date:
#############避免重复登记已经登记过的日期#######
Date.append(month+str(j))
else:
Date.append(str(re.sub('[\u4e00-\u9fa5]', '',date.iloc[i])))
date=pd.DataFrame(date)
#检查去年份是否成功
print(date)
#检查真正的日期序列是否生成成功
print(Date)
########以生成的日期依次查询当年的风向风级的情况###########
Time=[]
Land=[]
#海面的天气信息相较于陆地的对引航中断应当更直接
Sea=[]
for day in Date:
"""
该版本为完全排除空日期(无法由Date直接查询到的日期)
"""
if day in SheetNames:
Sheet=pd.read_excel(path,sheet_name=day)
Time.append(day)
Land.append(Sheet.iloc[1,0])
Sea.append(Sheet.iloc[2,0])
else:
#最严谨的方式是如果这一天没有读取到, 应当再读取前一天天气中"明天"的信息
#但是天气的记录格式不一, 所以这里选择若没有该天的天气记录, 就选择不录入
pass
#创建时间和天气关系的字典并生成表格
dic={'Day':Time,'Land':Land,'Sea':Sea}
Ori=pd.DataFrame(dic)
#检查生成风向风级原始数据表是否成功
print(Ori)
#######文本处理程序, 读取原始数据中的风向和风级信息###############
#创建空表格以备读写
tmp=pd.DataFrame()
processedPath='./ProcessedData/ProcessedData'+year+'.xlsx'
tmpFile=tmp.to_excel(processedPath)
#使用正则表达式进行信息读取
for orisentence in Sea:
WeatherDay=str(Time[Sea.index(orisentence)])
law=r"([今|明|后]天)?([东|西|偏]?[南|北|东|西]?)?[到]?([东|西|偏]?[南|北|东|西|阵]?)?风(\d)[\-]?([\d]?)级"
Weather=re.findall(law,orisentence,re.S)
'''
此处使用的正则表达式进行天气信息的筛选, 严格来说应该编辑状态自动机进行读取.
但是由于天气信息的撰写方式实在不一, 所以选用了一个通用性较高的方法.
若用Pytorch进行语言处理应当是最专业的, 限于能力水平并未使用.
'''
if Weather:
day=[]
#风向可能会发生改变, 如"东到东北风"等
diraction1=[]
diraction2=[]
#记录最小风级和最大风级
minscale=[]
maxscale=[]
for i in range(len(Weather)):
day.append(Weather[i][0])
#若有空白部分, 则从另一部分复制数据#
############风向部分的空白填充#############
if Weather[i][2]=='':
diraction1.append(Weather[i][1])
diraction2.append(Weather[i][1])
elif Weather[i][2]=='':
diraction1.append(Weather[i][2])
diraction2.append(Weather[i][2])
else:
diraction1.append(Weather[i][1])
diraction2.append(Weather[i][2])
##############风级部分的空白填充##########
if Weather[i][4]!='' and int(Weather[i][3])>int(Weather[i][4]):
#排除读到10的时候将1和0拆开
minscale.append(str(Weather[i][3])+str(Weather[i][4]))
maxscale.append(str(Weather[i][3])+str(Weather[i][4]))
elif Weather[i][4]=='':
#对仅有一个数字的进行复制粘贴处理
minscale.append(str(Weather[i][3]))
maxscale.append(str(Weather[i][3]))
else:
#其他情况正常入位
minscale.append(str(Weather[i][3]))
maxscale.append(str(Weather[i][4]))
#生成日期和天气关系的字典并生成表格
weatherdic={'日期':day,'风向1':diraction1,'风向2':diraction2,'小风级':minscale,'大风级':maxscale}
df=pd.DataFrame(weatherdic)
#在该文件中依次创建新worksheet,填入相应的df
with pd.ExcelWriter(processedPath,mode='a') as writer:
df.to_excel(writer,sheet_name=WeatherDay)
#清理读写期间产生的无用sheet(即Sheet1)
processedExcel=openpyxl.load_workbook(processedPath)
wastedSheet=processedExcel['Sheet1']
processedExcel.remove(wastedSheet)
#将读写完毕的表格存储起来
processedExcel.save(processedPath)
分析数据
风向分级确定准则
由上述的代码不难看出, 对于一段源文件的天气信息文本, 即使是同一正则表达式也可能会读出多条结果. 有的是同一天内的多条数据, 有的是不同天里的数据(这是因为某些日期的数据并不存在于对应的大风管制日期的表格中, 而是存在于某些相邻的大风管制日期.)
所以我们收集天气的策略是: 已知大风管制期间的天气记录并不止一天, 结合正则表达式的读取效果, 将读取数据的第一天和第二天之间的所有数据; 然后风级就是风向数据的最大值和最小值, 风向则是这些数据的第一对(记录数据时, 风向可能会以"东到东北风"的方式呈现, 所以风向会以成对的形式记录下来. 至于本来就只有一个风向的, 就视为这一对风向的两个元素都是相同的).
虽然这样的处理可能看似有些草率, 但是结合具体的天气信息文本不难看出, 出现异常情况往往都是都会是日期连报(如’今天、明天东到东北风’), 而且大风管制的日期也有可能是连续的, 所以即使按照上文所述的模糊识别方法, 也是有一定证据支撑的.
下面是具体的代码实现:
#! -*- coding=utf-8 -*-
from numpy import NAN, NaN, nan
import pandas as pd
#######################读取真正的风向风级##################
#逐年读取已经生成完毕的日期-天气表格
years=[str(x) for x in range(2011,2020+1)]
#预先分配list以存储读取的对应数据
Time=[]
Diraction1=[]
Diraction2=[]
minScale=[]
maxScale=[]
for year in years:
processedPath='./ProcessedData/ProcessedData'+year+'.xlsx'
f=pd.ExcelFile(processedPath)
SheetNames=f.sheet_names
#按天读取当天的风向风级
for day in SheetNames:
sht=pd.read_excel(processedPath,sheet_name=day)
date=list(sht['日期'].values)
dira1=list(sht['风向1'].values)
dira2=list(sht['风向2'].values)
scale1=list(sht['小风级'].values)
scale2=list(sht['大风级'].values)
#去除空白日期,即记录在'日期'列里实际记录的天数(今天,明天或后天)
date_brief=[sing for sing in date if sing==sing]
#记录日期所在位置的索引
date_index=[]
for sing in date_brief:
date_index.append(date.index(sing))
if len(date_brief)==1:
#若记录在列的只有一天,那么无论这一天是哪一天都将其作为当天的数据
diraction1=dira1[date_index[0]:]
diraction2=dira2[date_index[0]:]
minscale=min(scale1[date_index[0]:])
maxscale=max(scale2[date_index[0]:])
else:
#记录的不止一天的时候,就将第一天和第二天之间的数据收集起来
#即,有可能读取到的是"今天,后天",那么也会记录这两者之间的所有数据
diraction1=dira1[date_index[0]:date_index[1]]
diraction2=dira2[date_index[0]:date_index[1]]
minscale=min(scale1[date_index[0]:date_index[1]])
maxscale=max(scale2[date_index[0]:date_index[1]])
#预先分配list对风向的两个方向进行存储
d1list=[]
d2list=[]
#记录风向风级时先记录对应天的日期,为了避免重复还要加上年份的信息
Time.append(year+r'.'+day)
#在数据中会有空格和'阵'的数据,按照我们对于地理的理解即阵风为最大风级
#所以在记录时,将两天之间的所有风级进行比较,阵风为最大值所以必定包括在比较当中
for d1 in diraction1:
if str(d1)!='nan' and str(d1)!='阵':
d1list.append(str(d1))
for d2 in diraction2:
if str(d2)!='nan' and str(d2)!='阵':
d2list.append(str(d2))
#完成对于数据的清理之后,读取风向的规则即为其中的第一次风向信息的结果
#即,忽略了随着时间变化风向信息随之变化的过程。
#最严谨的方法是结合天气记录档案的最下方的引航中断时间(中午或者下午)来判断
#最正确的时间,但是仅仅借助正则表达式这个任务是异常困难的
Diraction1.append(d1list[0].replace('偏',''))
Diraction2.append(d2list[0].replace('偏',''))
#在使用正则表达式读取风向的时候,会读进'偏'字符
#在进行数据处理时则将偏字去除以备后期进行字典代换
minScale.append(minscale)
maxScale.append(maxscale)
#手动写入方向和度数的对应字典
word_to_num={'东':0,'西':180,'南':270,'北':90,'东南':315,'东北':45,'西南':225,'西北':135}
#预先分配读入读数的list
Diraction1_num=[]
Diraction2_num=[]
#使用已写好的字典对方向进行代换
for i in range(len(Time)):
Diraction1_num.append(word_to_num[Diraction1[i]])
Diraction2_num.append(word_to_num[Diraction2[i]])
#生成新字典并且生成表格
dira_and_scale={'日期':Time,'风向1':Diraction1,'风向1num':Diraction1_num,'风向2':Diraction2,'风向2num':Diraction2_num,'小风级':minScale,'大风级':maxScale}
df=pd.DataFrame(dira_and_scale)
processedPath='./ProcessedData/data.xlsx'
#将生成的表格记录下
file=df.to_excel(processedPath)
结论
首先是得到一张十年尺度的日期-风向风级的表格, 其中已经包含了对风向读为度数的列.
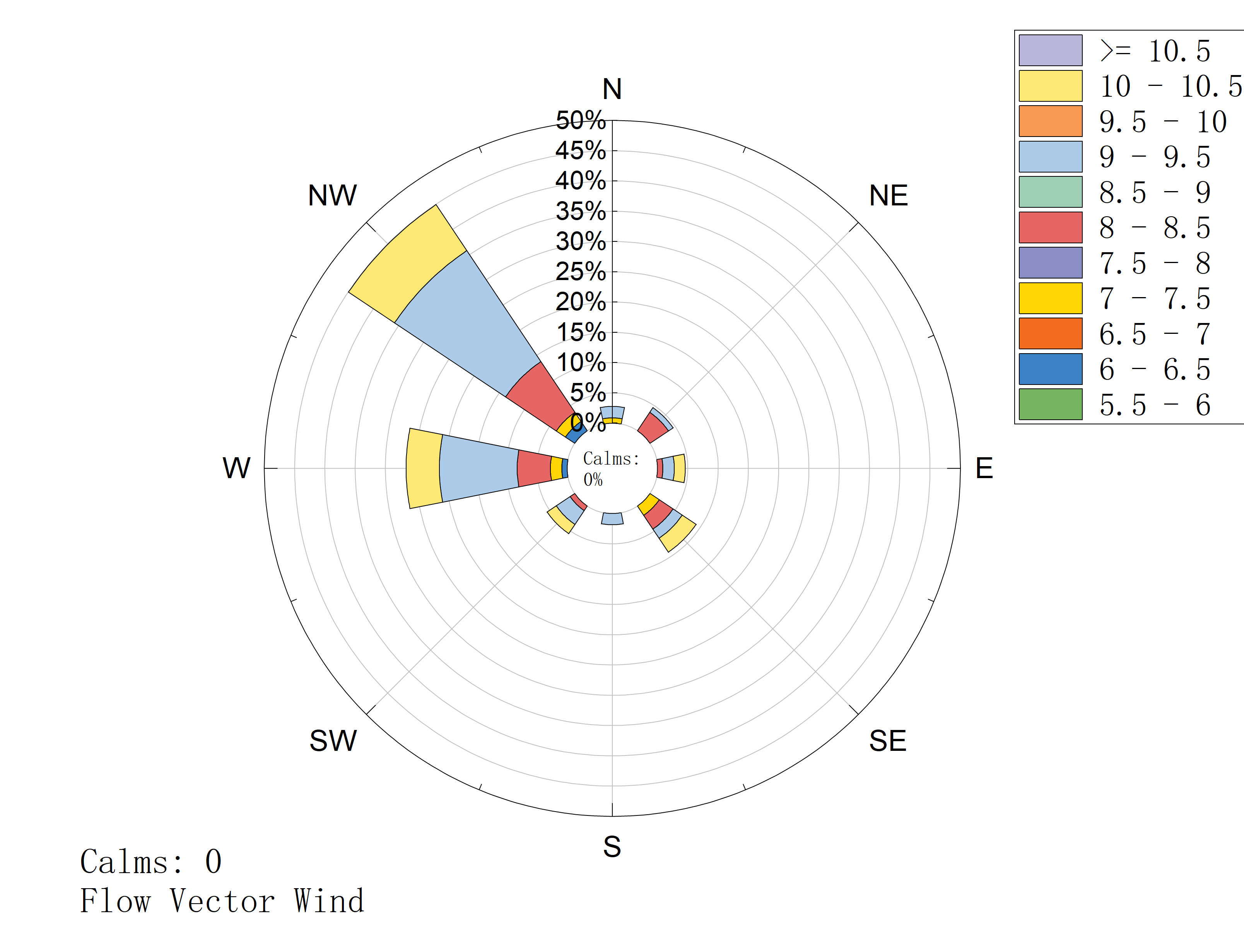
使用 OriginPro 的风向玫瑰图的绘制功能不难绘制出风向和风级在大风管制期间的规律. 由上述图可以分析得到的结论是:
- 大风管制发生时,风向各个风向都有,但是大多集中在西北方向,而且也是西北方向的风级最大;
- 风级一般要达到5级及以上时才会触发满足大风管制的条件.